Thoughts
Quick takes, hot thoughts, and random musings on tech, design, and life.
For some time now, I’ve been missing that motivation to build things. Without realizing it, I slipped into just following courses instead of actually creating stuff. So I’m treating this as a platform to express myself. Starting tomorrow, I’ll focus on building, sharing, and learning through real experience, no procrastination, no “only learning,” but actually doing. That’s the mindset I’m choosing from now on.
AI has come a long way. It’s no longer just about us explicitly telling systems what to do, modern AI models can now reason through problems and propose better approaches on their own.
Today, I was working on a reconciliation system where we were parsing documents and matching them against records in our CRM. As expected, there were mismatches, slight variations in names, formatting differences, and semantic inconsistencies that made exact matching unreliable.
Instead of hard-coding more rules, I prompted Claude Sonnet to suggest a smarter way to handle this. The goal was to detect semantic similarity and introduce a scoring system that could rank how closely two values matched, and then use that score to drive the reconciliation logic.
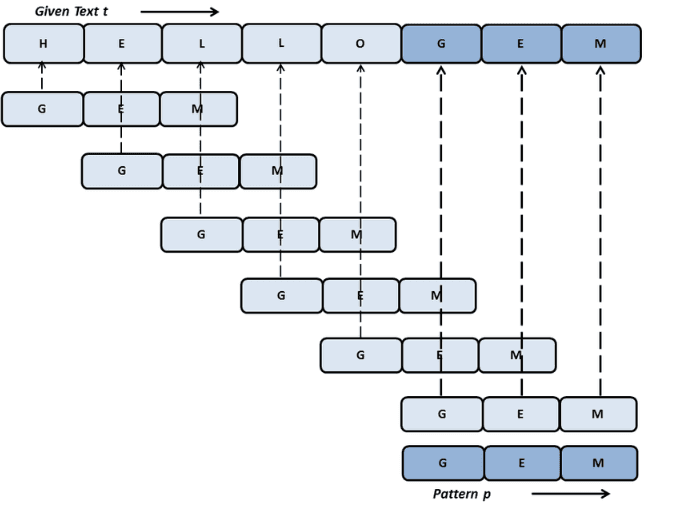
What the model proposed was the Levenshtein Distance algorithm. For those unfamiliar, it’s a fundamental string similarity algorithm that calculates the minimum number of single-character edits, insertions, deletions, or substitutions, required to transform one string into another.
Using this approach, the system can now assign a similarity score instead of relying on strict equality. Even though it’s a relatively small tweak, it significantly improves matching accuracy in real-world data.
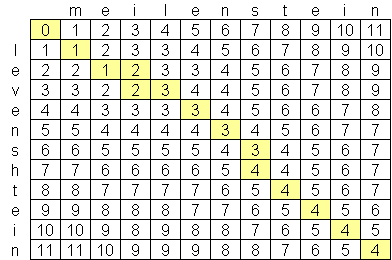
A Simple example for that would be:
- CRM value: “Jonathan Smith”
- Document value: “Jonathon Smyth”
Instead of treating this as a mismatch, the algorithm calculates how many character changes are needed to convert one string into the other.
- Fewer changes → higher similarity score
- Higher score → higher confidence match
Based on a predefined threshold (say, 85%), the system can automatically accept, flag, or reject the match.
This might seem like a basic improvement today, but it’s easy to see where this is heading. Very soon, you’ll be able to ask an LLM to scale a system end-to-end: selecting the most appropriate algorithms, optimizing performance, and adapting logic dynamically as the application grows.
That’s what really stood out to me, and that’s what I wanted to share.
I’ve realized there’s a real need for computer science folks to understand the financial world. I was never into finance — until around last September, when I suddenly felt I had to learn it.
My previous employer asked me to raise an invoice for my payouts. It was my first time, and honestly, I was nervous — worried I’d mess something up. Everything went fine… until I got paid and noticed about 10% missing. When I asked the CEO, he explained it was deducted as income tax, and that I could claim it back at the end of the financial year. That’s when it hit me: you really do need to know this stuff.
Also, this article explains finance using graph structures in a super intuitive way — highly recommend giving it a read: https://martin.kleppmann.com/2011/03/07/accounting-for-computer-scientists.html
Definitely worth it!